 Index-based ETFs and index funds are popular choices for investors these days. The low costs and simplicity are a big selling points. Not to mention the fund marketing blitz reminding us how often actively managed funds fail to beat the S&P 500 index. But do you know how that underlying index works? Is it built to be a good investment strategy? Or should alternative index weighting methods be used?
Index-based ETFs and index funds are popular choices for investors these days. The low costs and simplicity are a big selling points. Not to mention the fund marketing blitz reminding us how often actively managed funds fail to beat the S&P 500 index. But do you know how that underlying index works? Is it built to be a good investment strategy? Or should alternative index weighting methods be used?
A stock index is used to measure the performance of a group of stocks. To do this a weighting method is used, which puts more emphasis on weighting on stocks that meet specific criteria. In turn, those stocks represent a greater part of the index.
Since index funds are built to track a specific index, a fund uses the same weighting method on the stocks it owns.
Most of the major market indices are based on a market cap weighting. In the past few years, several fund companies started offering alternative weighted index funds. But it all started with a price-weighted index.
Price Weighted Index
The Dow is built on a price-weighted method. It’s the oldest and rarely used index method built around an average of the underlying stock’s prices. A higher priced stock carries a higher weighting in the index. So a $100 stock would have more influence than a $10 stock. Which tends to overweight the index based only on price. Over time, the index needs to adjust for stock splits, dividends, and stock replacement.
Pros
The only advantage is it’s easy to calculate.
Cons
The big argument against a price-weighted method is its overemphasis on share price regardless of fundamentals. Plus, price only tells you what someone is willing to pay. It says nothing about the overall performance of the stocks in the index. This is why it’s rarely used.
Market Cap Weighted Index
Market cap is the most common weighting method used by an index. Market cap or market capitalization is the standard way to measure the size of the company. You might have heard of large, mid, or small-cap stocks? Large-cap stocks carry a higher weighting in this index. And most of the major indices, like the S&P 500, use the market cap weighting method.
Stocks are weighted by the proportion of their market cap to the total market cap of all the stocks in the index. As a stock’s price and market cap rise, it gains a bigger weighting in the index. In turn, the opposite, lower stock price and market cap, push its weighting down in the index.
Pros
Proponents argue that large companies have a bigger effect on the economy and are more widely owned. So they should have a bigger representation when measuring the performance of the market. Which is true.
Cons
It doesn’t make sense as an investment strategy. According to a market-cap-weighted index, investors would buy more of a stock as its price rises and sell the stock as the price falls. This is the exact opposite of the buy low, sell high mentality investors should use.
Eventually, you would have more money in overpriced stocks and less in underpriced stocks. Yet most index funds follow this weighting method.
Equal Weighted Index
An equal-weighted index is the first of two alternative weightings used in smart-beta funds. It’s the easiest to explain because each stock holds the same importance regardless of fundamentals, market cap, or price. Simply, each stock in the index has the same weighting. In return, each stock equally contributes to the performance of the index. So, an index of 500 stocks, like the S&P 500 Equal Weighted index, each stock represents 0.2% of the index.
Pros
An equal-weighted index removes the emphasis on market cap. So the index fund isn’t forced to buy more overpriced stocks and sell underpriced stocks. But an equal-weighted index fund doesn’t eliminate it completely. It just tends to be more random, since each stock has the same weighting.
Cons
The equal weighting poses some problems. Price changes cause a high turnover. Shares are constantly bought and sold to keep the equal weighting. This adds to the cost of the fund and can add to your tax liabilities too. This makes ETFs the preferred choice for an equal-weighted index. Lastly, equal-weighted index funds are limited by their size. The fund can easily outgrow the smallest stock in the index.
Fundamentally Weighted Index
A fundamentally weighted index puts an emphasis on one or more factors like sales, book value, dividends, cash flow, or earnings. Stocks that meet those factors get a higher weighting in the index.
Pros
The biggest advantage is the emphasis on performance factors. This removes the randomness of equal weighting and the backward approach that market cap weighting provides. That assumes, of course, that you invest based on those fundamental factors.
Cons
It doesn’t take much imagination to view this as actively managed, despite the contrary. And higher costs become a concern too. More important, any fundamentally weighted index fund requires enough investors actually use that exact strategy.
It requires knowledge and understanding of each factor. Any investor that knows this, can easily build their own portfolio using a combination of funds that have similar results.
Cap Weighted Vs. Equal Weighted Comparison
It’s difficult to compare all four weighting methods. Either, the index funds haven’t been around long enough to make it worthwhile or the funds take some liberties in what stocks make up the fund, despite the fact it’s based on a particular index. Some stocks are replaced by stocks not found in the index or excluded entirely.
For now, the best way to compare the difference is between the cap-weighted S&P 500 and the S&P 500 equal-weighted index. Most of the S&P 500 index funds are cap-weighted. So it isn’t hard to find one. The Guggenheim S&P 500 (RSP) is an equal-weighted index fund and one of the first smart beta funds (find out more here).
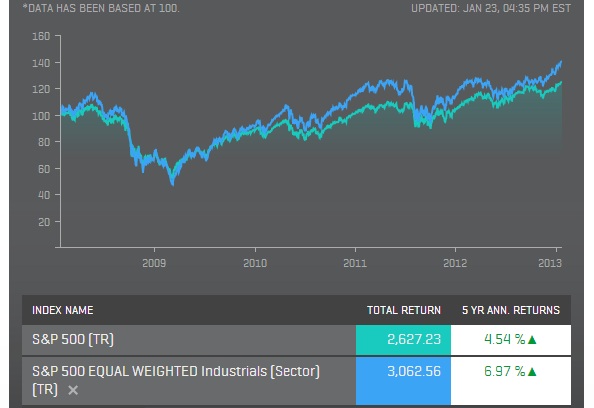
The chart shows the S&P 500 equal-weighted index outperformed in a rising market and underperformed in a falling market. The fact it’s only a five-year window needs to be taken into consideration, even with the 2.43% higher annual return. Since alternative weighted funds are relatively new, it’s difficult to get a good idea of their long-term performance potential.
Is there a benefit to equal-weighted versus cap-weighted? Since money isn’t concentrated in large-cap stocks, it offers a better representation of mid and small-cap stock performance. Thus the higher return. But it takes on the extra risk associated with those stocks too. It tends to over-exaggerate the performance of a regular S&P 500 index fund. And it’s a good representation of how asset allocation can impact performance.
Defensive portfolios might consider a regular S&P 500 index fund. Portfolios wanting more growth and risk should look at an S&P 500 equal-weighted index fund.
If the popularity of equal-weighted funds or other alternative weighted funds takes off, you can expect other fund families to get on board. The possibilities could open up some great opportunities in sector-specific funds. With a little extra research, you might find an alternative weighting method that fits your investment strategy.